Same reward model — now scoring noisy diffusion latents directly, at the quality you expect on clean images. The first practical recipe.
②What we do
③The impact
One fix Replace the heavy effort to denoise a noisy latent to calculate a pixel reward → with a direct StitchVM score. The four wins that fall out ↓
DPS
3.2× faster
higher quality · ↓50% GPU memory
FK steering
33% lower cost
via a more efficient scaling axis
DRaFT
+30% GenEval
& 22–26% fewer GPU-hours
DiffusionNFT
55%+ GPU-h saved
2.3× faster training
Most diffusion alignment methods come down to answering this question along the denoising trajectory.
Diffusion sampling will turn the noisy latent $\mathbf z_t$ into a final generation $\mathbf x_0$. Every alignment method has to answer this from a glance at $\mathbf z_t$ alone: how valuable will the final $\mathbf x_0$ be?
Formally, this is the value function $V_t(\mathbf z_t)$ — the expected reward of the clean image $\mathbf z_t$ will eventually denoise to:
$$V_t(\mathbf z_t) \;=\; \mathbb E\!\left[\,r(\mathbf z_0)\,\big|\,\mathbf z_t\right].$$
Across both inference-time and training-time alignment, evaluating $V_t$ is the common need — three examples:
So methods approximate $V_t$ instead — each approximation with cost and estimation problems.
Learning $V_t$ directly would be the cleanest fix — no bias, no variance, no extra evaluations. But matching a foundation-scale pixel reward model (CLIP, HPSv2, Aesthetic Predictor) on noisy latents has meant training at their scale, redone for every new backbone or reward. So practitioners approximate $V_t$ instead. Two workarounds dominate — each with its own price:
Practitioners settle for the red rows above because matching pixel-reward quality on noisy latents has meant retraining at foundation scale. StitchVM avoids that: it transfers, instead of retraining.
At the cost of a short finetune — not retraining anything from scratch.
Why this works: at the right depth, the internal features of a pretrained diffusion model are almost linearly compatible with those of a pretrained pixel reward model. So we keep the head of the diffusion model frozen (already native to noisy latents), keep the tail of the reward model (it already produces the score), and join them with a small stitching layer — initialised by a closed-form linear fit, then briefly finetuned together with the reward tail on unlabeled images. The stitched model inherits the reward model's predictive skill, but now operates directly on noisy latents.
The result is a noisy-latent value model at pixel-reward quality, built in hours on a single GPU — no training from scratch, just a transfer.
④ THE REACH · WHY IT MATTERS
Build $V_t$ once. Drop it into every alignment recipe — inference-time guidance, particle sampling, training-time finetuning — and watch each one get cheaper at the same time.
INFERENCE-TIME ALIGNMENT
TRAINING-TIME ALIGNMENT
⑤ THE WINS · RESULTS
The same StitchVM — one noisy-latent $V_t$, built once by stitching — plugged into four very different alignment methods. Across DPS, FK steering, DRaFT, and DiffusionNFT it delivers better quality with materially lower compute.
DPS · gradient guidance
3.2× faster
higher quality on nearly every reward×metric pair · ↓50% peak GPU memory
FK steering · particle sampling
33% lower cost
via a more efficient scaling axis — $(N{=}8, M{=}6)$ matches standard FKS at $N{=}14$
DRaFT · direct reward finetuning
+30% GenEval
higher score across all metrics & 22–26% fewer GPU-hours
DiffusionNFT · RL post-training
55%+ GPU-h saved
2.3× faster training, higher scores on every metric
RESULT 1 · NOISY-LATENT VALUE MODEL
Across three diffusion backbones (SD 3.5 Medium/Large, FLUX) and four reward models (OpenAI CLIP, DFN-CLIP, HPSv2, Aesthetic Predictor), StitchVM closely tracks the original clean reward model at low noise and degrades gracefully as noise rises — substantially beating both VAE-stitching and NoisyCLIP retraining at LAION-400M scale. The expensive "train a noisy-latent reward from scratch" baseline is no longer needed.
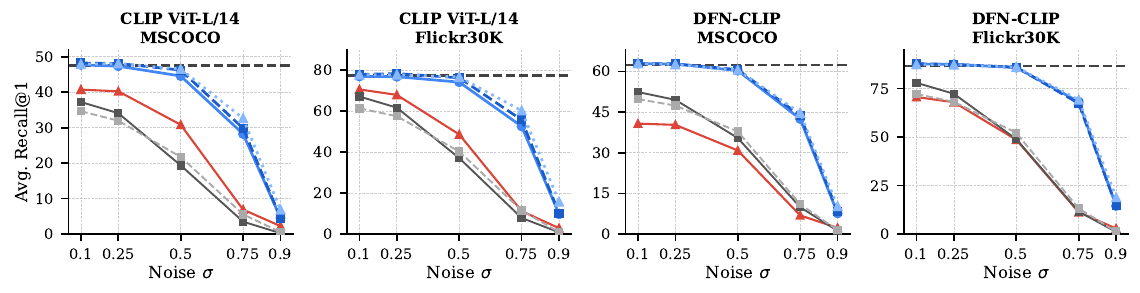
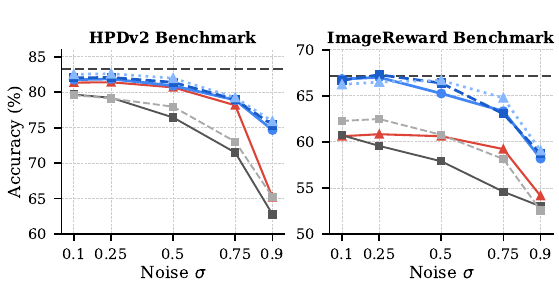
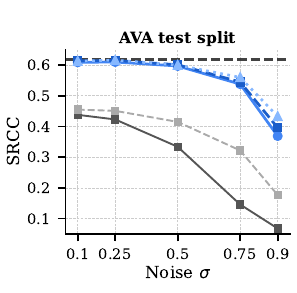
Results of StitchVM on latents with different noise levels. $\oplus$ denotes stitching of a reward model with a pretrained diffusion module (VAE encoder or DiT). StitchVM (blue) tracks the clean reward (dashed line) far better than VAE-stitching or NoisyCLIP, across retrieval, preference, and aesthetic benchmarks.
RESULT 2 · A NEW SCALING AXIS FOR FK STEERING
Cheap $V_t$ scoring unlocks a second scaling axis on FK steering: instead of adding more particles ($N$), each particle spawns $M$ proposals scored by StitchVM at near-zero marginal cost (partial-DiT inference + stitching head, shared with the next denoising step). On FLUX with HPSv2 reward, FK steering + StitchVM at $(N{=}8, M{=}6)$ matches standard FKS at $N{=}14$ with 33% less compute, and is strictly above the $N$-only curve everywhere.
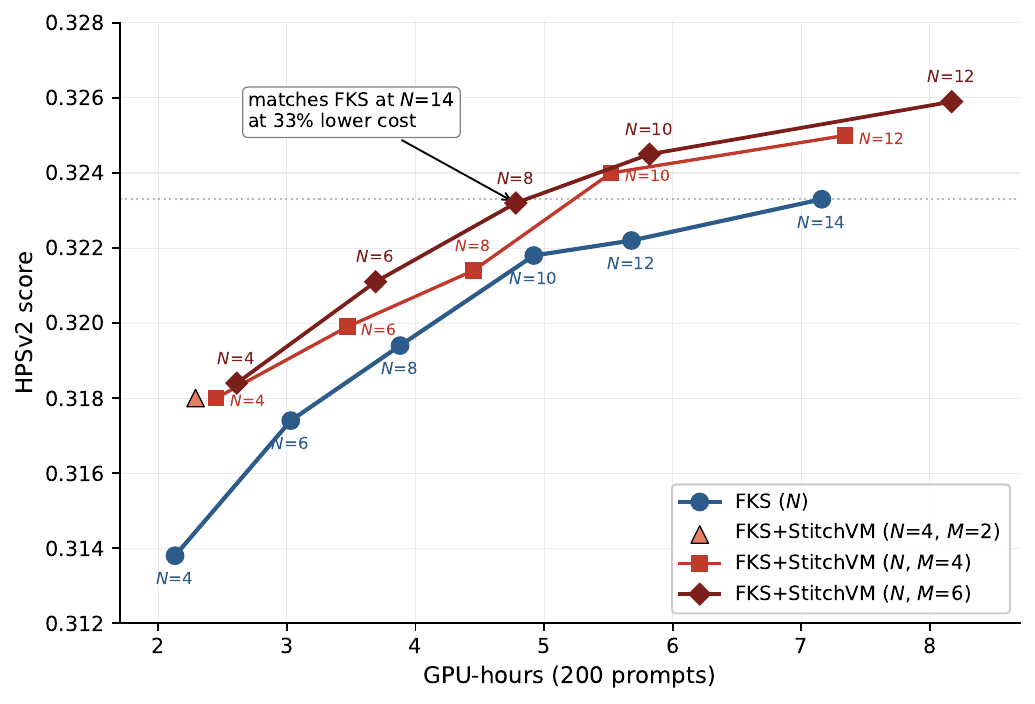
HPSv2 score vs. GPU-hours on FLUX. Blue: standard FK steering scaling $N$. Red/dark-red: FK steering + StitchVM scaling $M$ at fixed $N$. The StitchVM curves dominate the standard one across the whole compute range.
RESULT 3 · TRAINING-TIME ALIGNMENT
On SD 3.5 Medium at $512{\times}512$ with DFN-CLIP and HPSv2 as training rewards, replacing the terminal reward $r(\mathbf z_0)$ with the StitchVM value $V_t(\mathbf z_\tau)$ (early-stop at intermediate $\tau$) cuts wall-clock training cost dramatically and raises every metric:
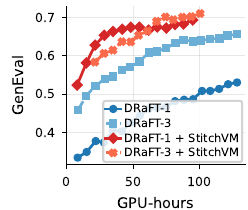
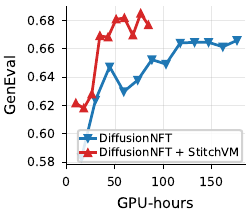
GenEval vs. GPU-hours on SD 3.5 Medium with DFN-CLIP + HPSv2 reward. Red: with StitchVM. Blue: baseline. Adding StitchVM matches the baseline at roughly half the GPU-hours and keeps climbing past it.
Each StitchVM itself is a one-time, lightweight build: $\approx$ 10 GPU-hours at $512{\times}512$ (24–32 GPU-h at $1024{\times}1024$) on GH200 — trivial relative to the savings it enables downstream.
@article{go2026stitchvm,
title = {Stitched Value Model for Diffusion Alignment},
author = {Go, Hyojun and Chung, Hyungjin and Truong, Prune and Bhat, Goutam
and Mi, Li and An, Zhaochong and Zhao, Zixiang and Narnhofer, Dominik
and Belongie, Serge and Tombari, Federico and Schindler, Konrad},
journal = {arXiv preprint arXiv:2605.19804},
year = {2026}
}


