
I am an ELLIS PhD student jointly between ETH Zurich (Photogrammetry and Remote Sensing group) and Google, advised by Prof. Konrad Schindler and Dr. Federico Tombari. I also work closely with Dr. Goutam Bhat and Dr. Prune Truong at Google. My research interests include generative models (especially Diffusion Models) and 3D generation.
Previously, I worked as a Research Scientist for my mandatory military service at Twelvelabs and Riiid (Korean military service companies). Prior to that, I received my M.S. degree from KAIST.
Research interests.
- 3D Generation. My ultimate research goal is to generate and edit immersive 3D and 4D world scenes. Building on the power of generative models, I am interested in inducing scene geometry priors, representations, and physics into them.
- Diffusion / Flow-based Models (Few-step Generation). Diffusion/flow models naturally lend themselves to multi-task learning, where a single model learns denoising across noise levels. I am interested in training strategies that encourage positive transfer between tasks to enable high-quality generation with fewer steps and lower compute.
Education
-
 ETH ZurichPh.D. in 3D Generation (ELLIS, with Google)Apr. 2025 - present
ETH ZurichPh.D. in 3D Generation (ELLIS, with Google)Apr. 2025 - present -
 KAISTM.S. in Electrical EngineeringMar. 2020 - Feb. 2022
KAISTM.S. in Electrical EngineeringMar. 2020 - Feb. 2022 -
 Hanyang UniversityB.S. in Electrical EngineeringMar. 2015 - Aug. 2019
Hanyang UniversityB.S. in Electrical EngineeringMar. 2015 - Aug. 2019
Experience
-
 TwelvelabsResearch Scientist (Mandatory military service) — Video Language Models (Pegasus-v1)Sep. 2023 - Mar. 2025
TwelvelabsResearch Scientist (Mandatory military service) — Video Language Models (Pegasus-v1)Sep. 2023 - Mar. 2025 -
 RiiidResearch Scientist (Mandatory military service) — Diffusion ModelsMar. 2022 - Aug. 2023
RiiidResearch Scientist (Mandatory military service) — Diffusion ModelsMar. 2022 - Aug. 2023
Invited Talks
-
Google Invited TalkOct. 2025
-
AI Seoul Invited Talk — "Addressing Negative Transfer in Diffusion Models" (Seoul City Hall)Feb. 2024
News
Publications
2026
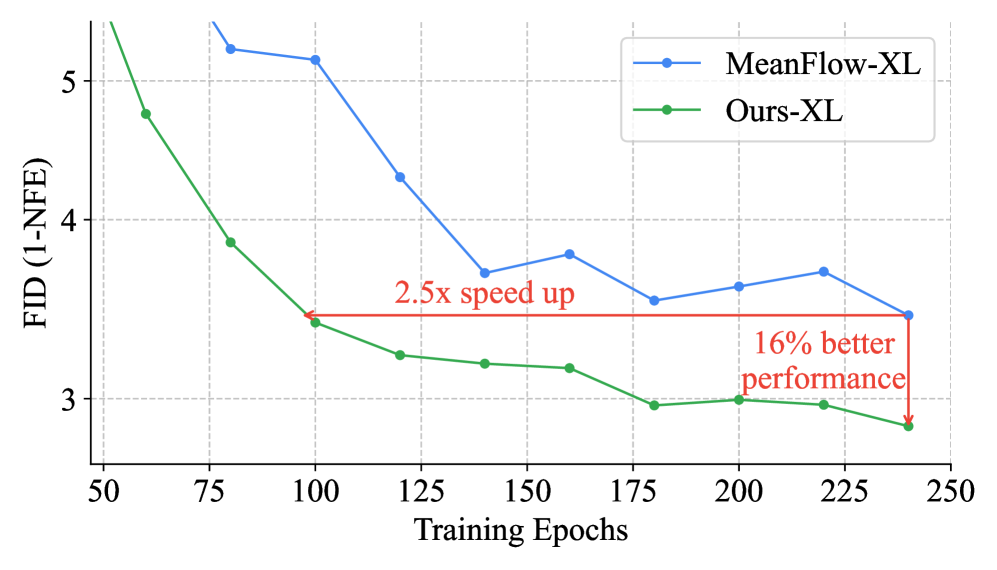
Understanding, Accelerating, and Improving MeanFlow Training
Jin-Young Kim*, Hyojun Go*, Lea Bogensperger, Julius Erbach, Nikolai Kalischek, Federico Tombari, Konrad Schindler, Dominik Narnhofer (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
Understanding, Accelerating, and Improving MeanFlow Training
Jin-Young Kim*, Hyojun Go*, Lea Bogensperger, Julius Erbach, Nikolai Kalischek, Federico Tombari, Konrad Schindler, Dominik Narnhofer (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2026
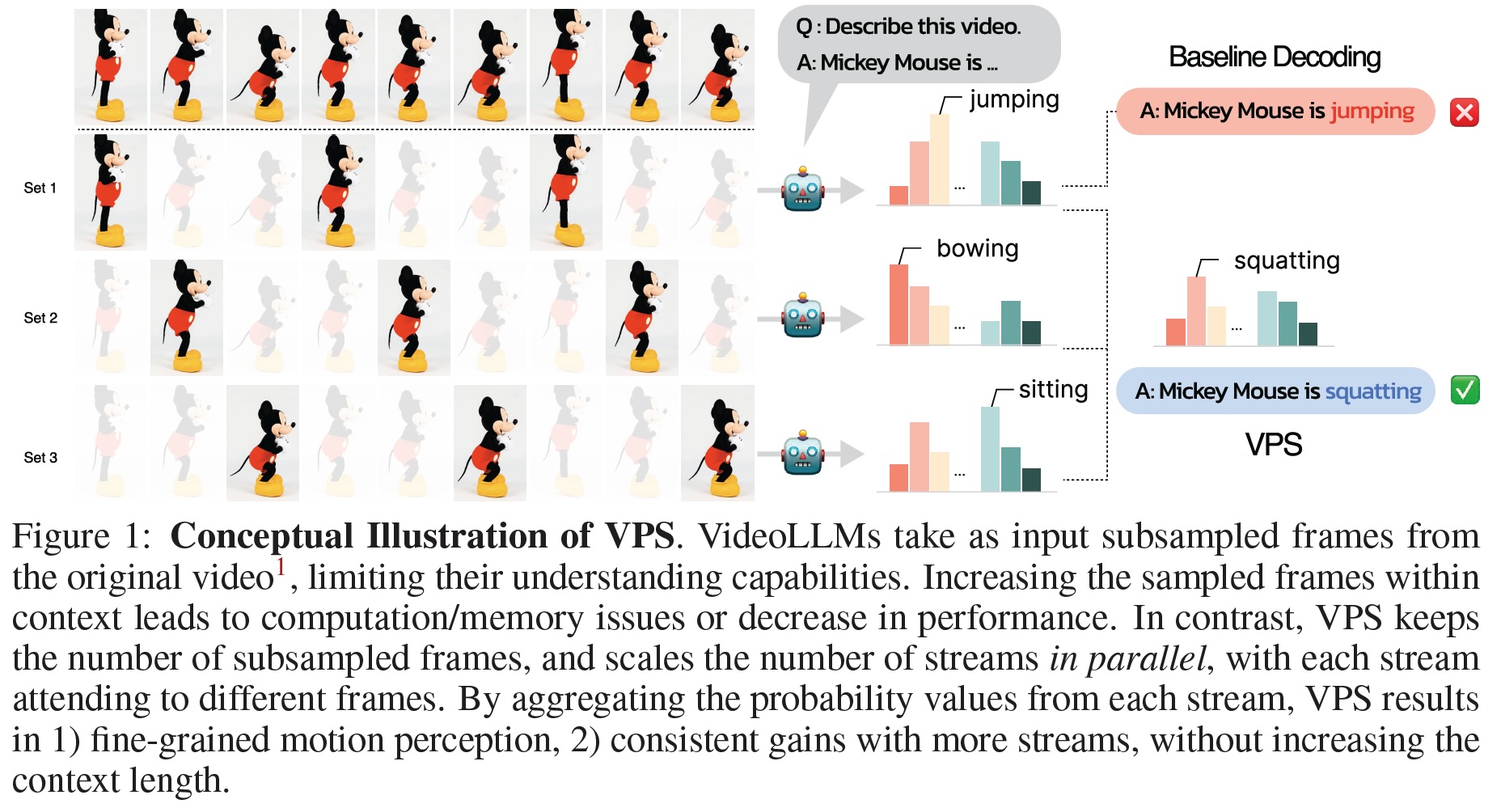
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Hyungjin Chung, Hyelin Nam, Jiyeon Kim, Hyojun Go, Byeongjun Park, Junho Kim, Joonseok Lee, Seongsu Ha, Byung-Hoon Kim
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Findings 2026
Video Parallel Scaling: Aggregating Diverse Frame Subsets for VideoLLMs
Hyungjin Chung, Hyelin Nam, Jiyeon Kim, Hyojun Go, Byeongjun Park, Junho Kim, Joonseok Lee, Seongsu Ha, Byung-Hoon Kim
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Findings 2026
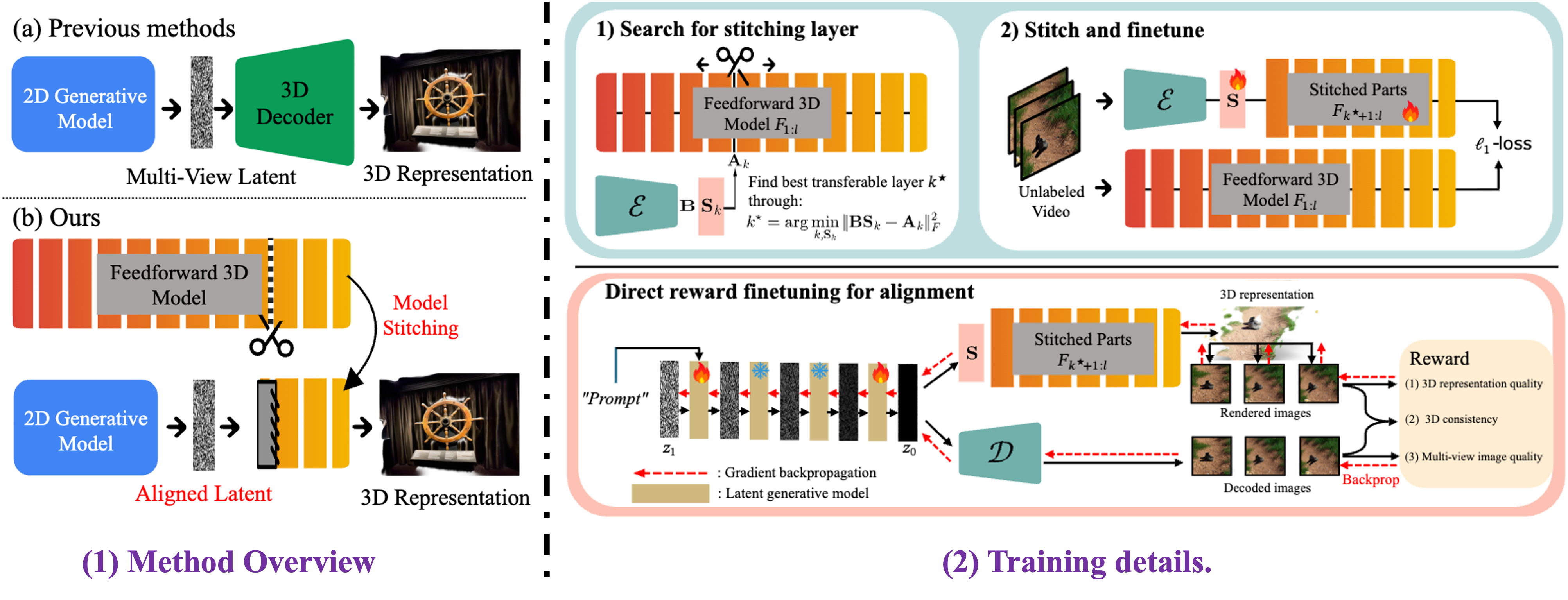
VIST3A: Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator
Hyojun Go, Dominik Narnhofer, Goutam Bhat, Prune Truong, Federico Tombari, Konrad Schindler
International Conference on Learning Representations (ICLR) 2026 Oral
VIST3A: Text-to-3D by Stitching a Multi-view Reconstruction Network to a Video Generator
Hyojun Go, Dominik Narnhofer, Goutam Bhat, Prune Truong, Federico Tombari, Konrad Schindler
International Conference on Learning Representations (ICLR) 2026 Oral
2025
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Byeongjun Park*, Hyojun Go*, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim (* equal contribution)
International Conference on Computer Vision (ICCV) 2025
SteerX: Creating Any Camera-Free 3D and 4D Scenes with Geometric Steering
Byeongjun Park*, Hyojun Go*, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim (* equal contribution)
International Conference on Computer Vision (ICCV) 2025

VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Hyojun Go*, Byeongjun Park*, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim (* equal contribution)
International Conference on Computer Vision (ICCV) 2025
VideoRFSplat: Direct Scene-Level Text-to-3D Gaussian Splatting Generation with Flexible Pose and Multi-View Joint Modeling
Hyojun Go*, Byeongjun Park*, Hyelin Nam, Byung-Hoon Kim, Hyungjin Chung, Changick Kim (* equal contribution)
International Conference on Computer Vision (ICCV) 2025

SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Hyojun Go*, Byeongjun Park*, Jiho Jang, Jin-Young Kim, Soonwoo Kwon, Changick Kim (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
SplatFlow: Multi-View Rectified Flow Model for 3D Gaussian Splatting Synthesis
Hyojun Go*, Byeongjun Park*, Jiho Jang, Jin-Young Kim, Soonwoo Kwon, Changick Kim (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2025
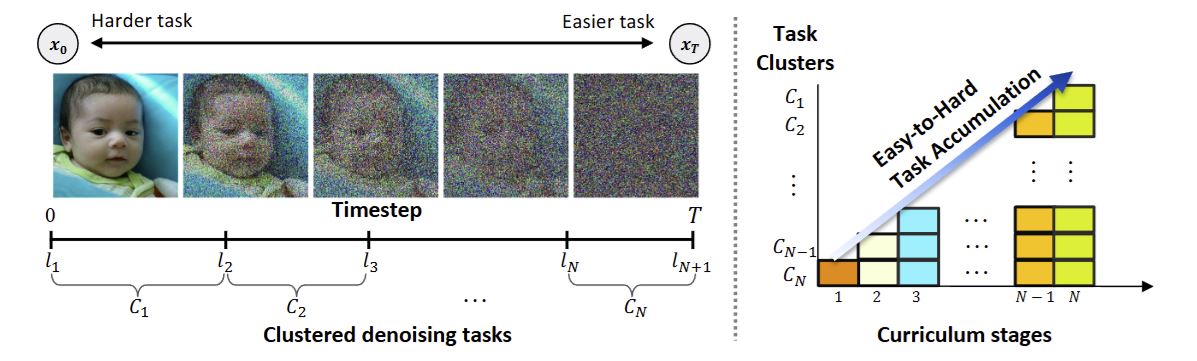
Denoising Task Difficulty-based Curriculum for Training Diffusion Models
Jin-Young Kim*, Hyojun Go*, Soonwoo Kwon, Hyun-Gyoon Kim (* equal contribution)
International Conference on Learning Representations (ICLR) 2025
Denoising Task Difficulty-based Curriculum for Training Diffusion Models
Jin-Young Kim*, Hyojun Go*, Soonwoo Kwon, Hyun-Gyoon Kim (* equal contribution)
International Conference on Learning Representations (ICLR) 2025
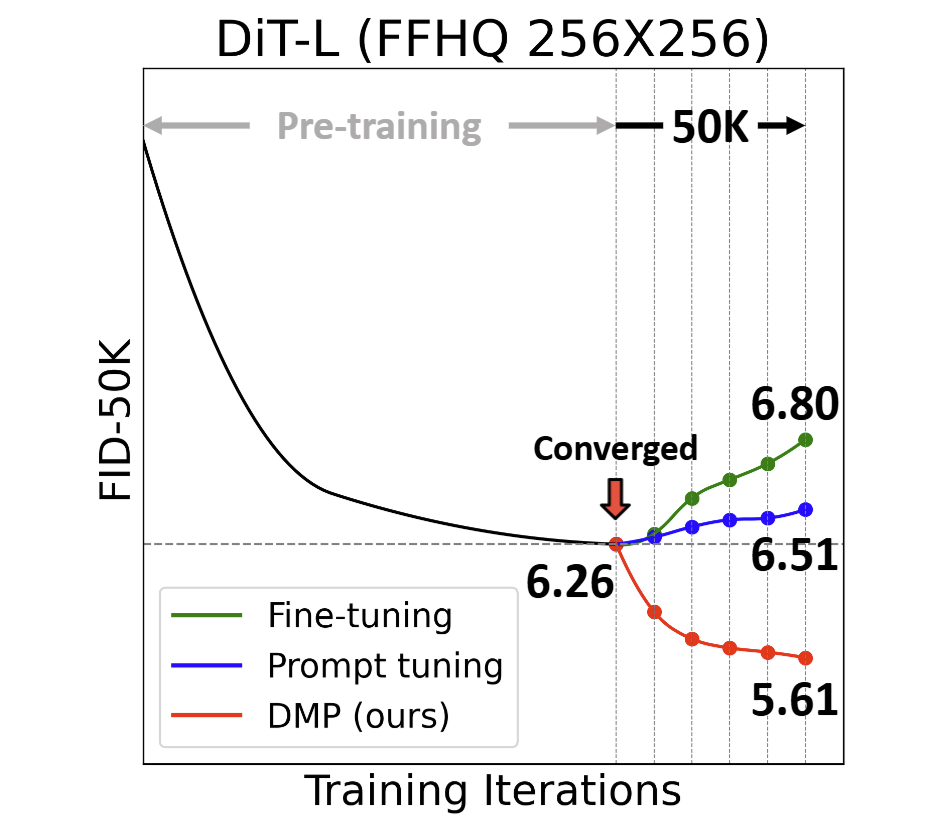
Diffusion Model Patching via Mixture-of-Prompts
Seokil Ham*, Sangmin Woo*, Jin-Young Kim, Hyojun Go, Byeongjun Park, Changick Kim (* equal contribution)
AAAI Conference on Artificial Intelligence (AAAI) 2025
Diffusion Model Patching via Mixture-of-Prompts
Seokil Ham*, Sangmin Woo*, Jin-Young Kim, Hyojun Go, Byeongjun Park, Changick Kim (* equal contribution)
AAAI Conference on Artificial Intelligence (AAAI) 2025
2024
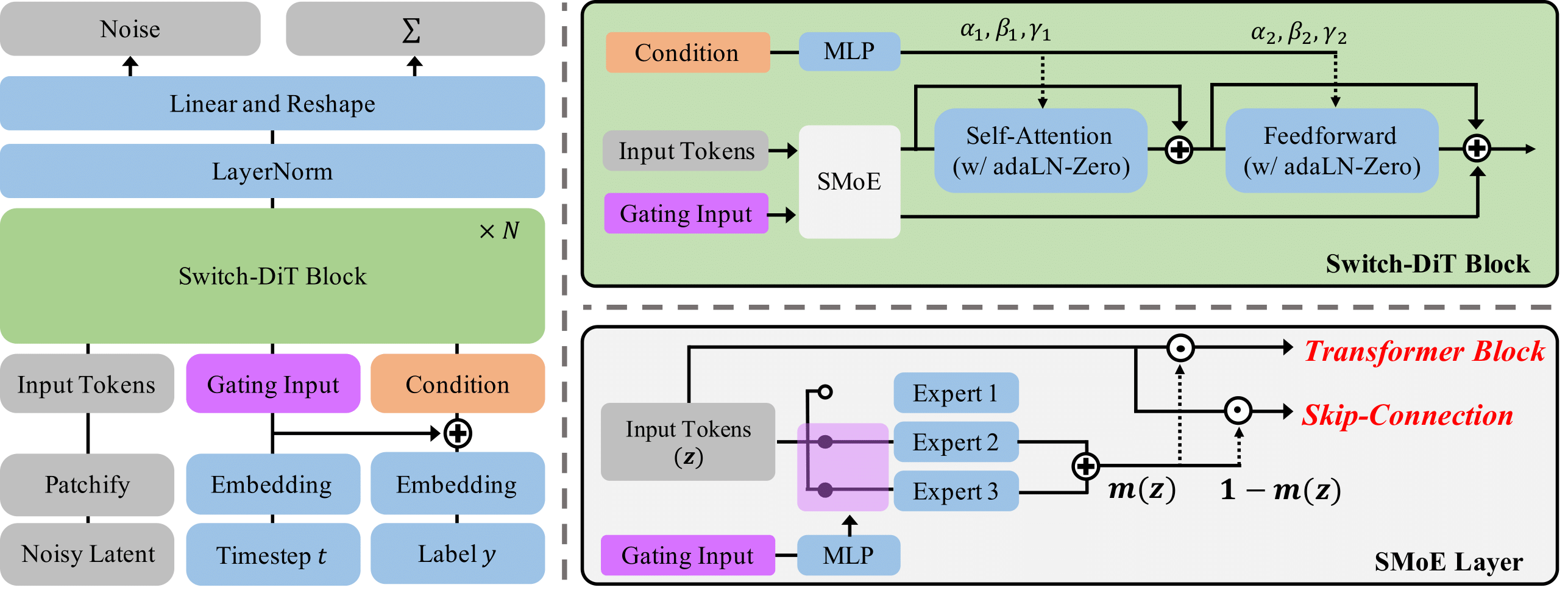
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Byeongjun Park, Hyojun Go, Jin-Young Kim, Sangmin Woo, Seokil Ham, Changick Kim
European Conference on Computer Vision (ECCV) 2024
Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts
Byeongjun Park, Hyojun Go, Jin-Young Kim, Sangmin Woo, Seokil Ham, Changick Kim
European Conference on Computer Vision (ECCV) 2024
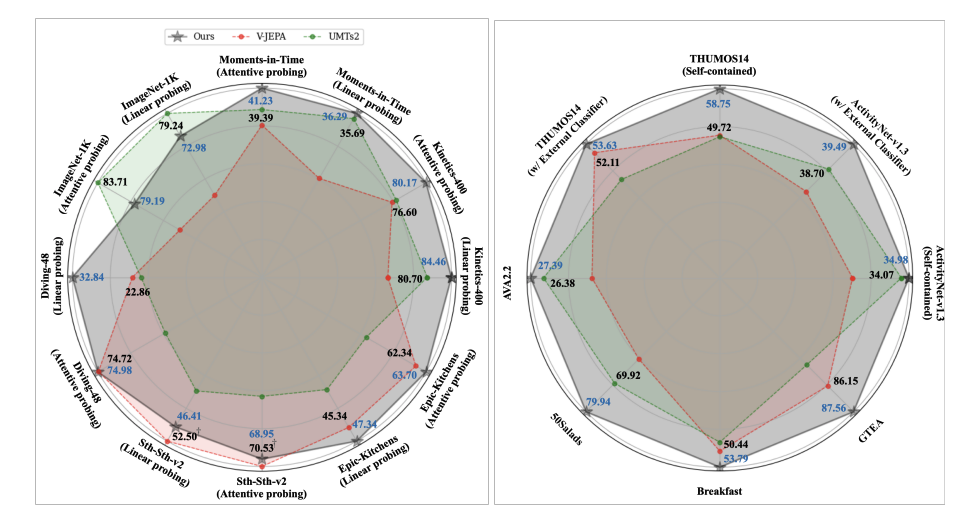
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Twelvelabs Team
Technical Report 2024
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
Twelvelabs Team
Technical Report 2024
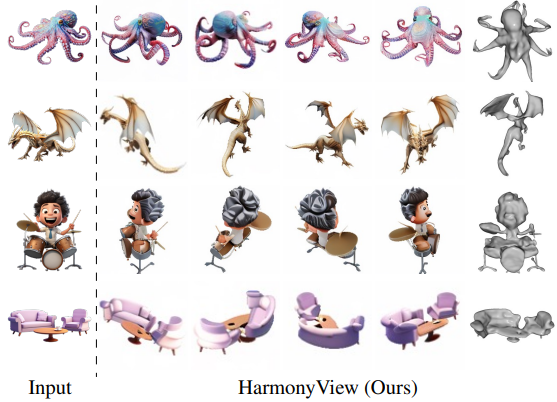
HarmonyView: Harmonizing Consistency and Diversity in One-Image-to-3D
Sangmin Woo*, Byeongjun Park*, Hyojun Go, Jin-Young Kim, Changick Kim (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
HarmonyView: Harmonizing Consistency and Diversity in One-Image-to-3D
Sangmin Woo*, Byeongjun Park*, Hyojun Go, Jin-Young Kim, Changick Kim (* equal contribution)
IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) 2024
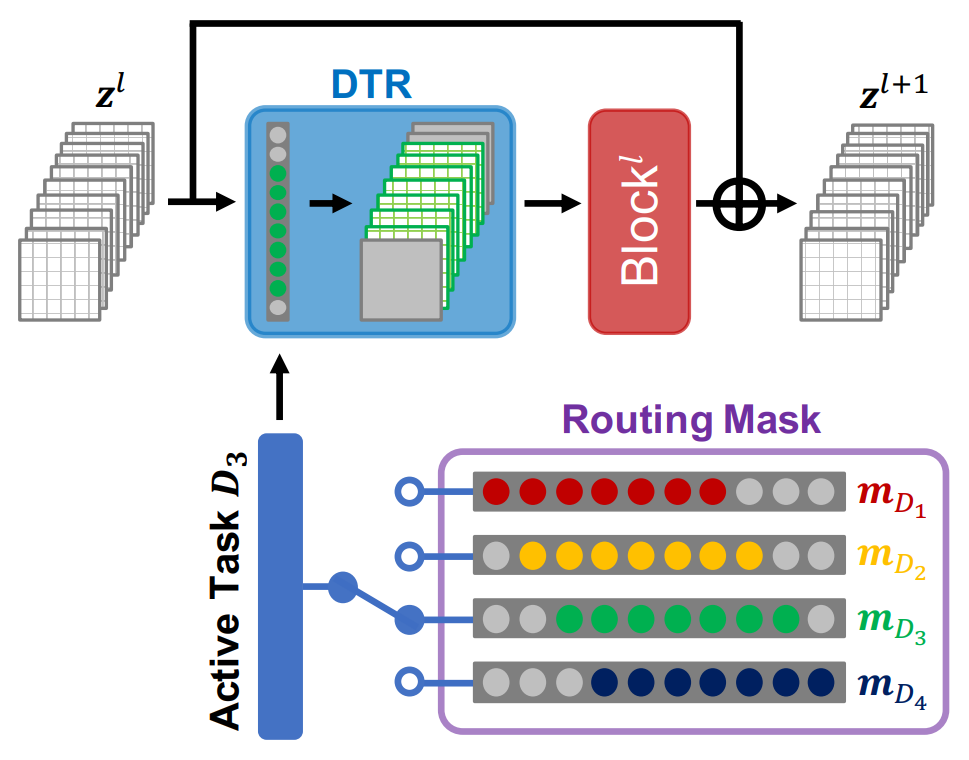
Denoising Task Routing for Diffusion Models
Byeongjun Park*, Sangmin Woo*, Hyojun Go*, Jin-Young Kim*, Changick Kim (* equal contribution)
International Conference on Learning Representations (ICLR) 2024
Denoising Task Routing for Diffusion Models
Byeongjun Park*, Sangmin Woo*, Hyojun Go*, Jin-Young Kim*, Changick Kim (* equal contribution)
International Conference on Learning Representations (ICLR) 2024
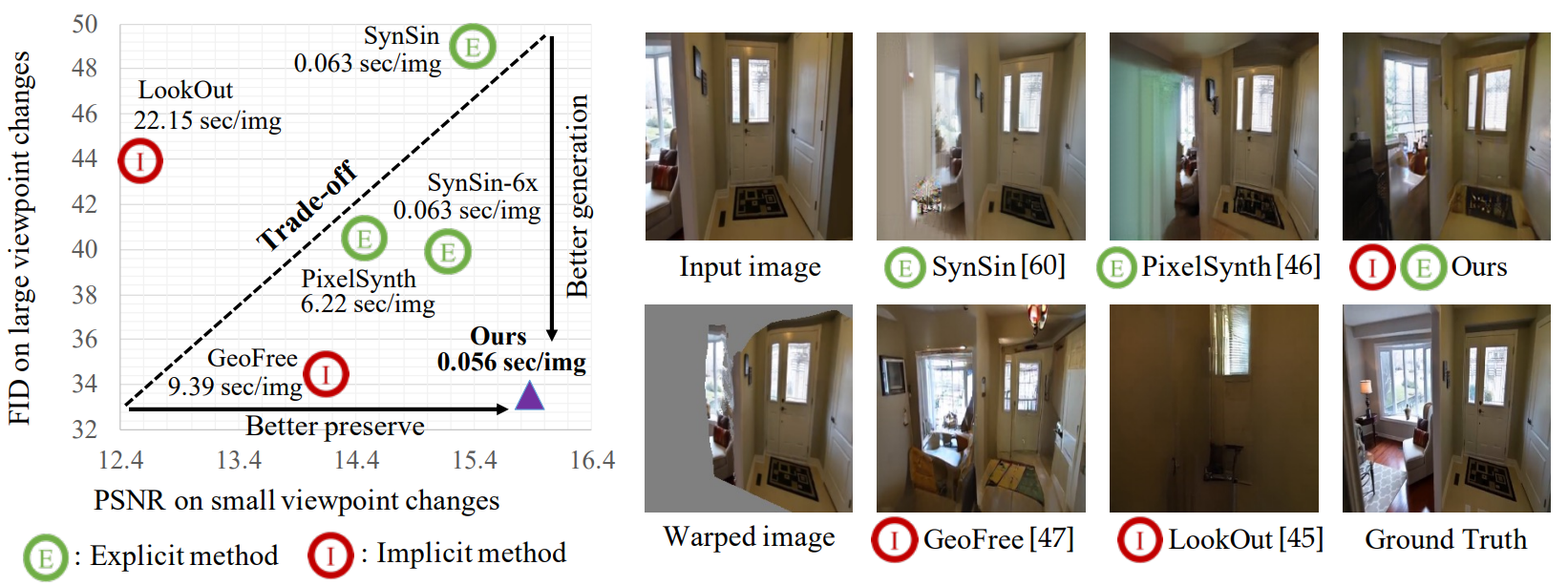
Bridging Implicit and Explicit Geometric Transformation for Single-Image View Synthesis
Byeongjun Park*, Hyojun Go*, Changick Kim (* equal contribution)
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2024
Bridging Implicit and Explicit Geometric Transformation for Single-Image View Synthesis
Byeongjun Park*, Hyojun Go*, Changick Kim (* equal contribution)
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2024
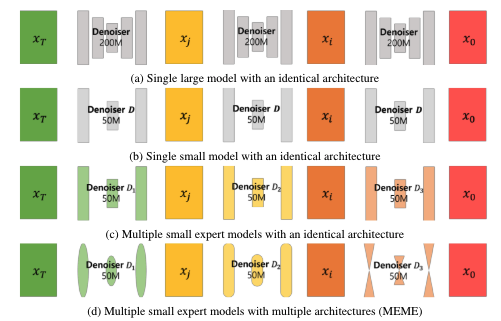
Multi-Architecture Multi-Expert Diffusion Models
Yunsung Lee*, JinYoung Kim*, Hyojun Go*, Myeongho Jeong, Shinhyeok Oh, Seungtaek Choi (* equal contribution)
AAAI Conference on Artificial Intelligence (AAAI) 2024
Multi-Architecture Multi-Expert Diffusion Models
Yunsung Lee*, JinYoung Kim*, Hyojun Go*, Myeongho Jeong, Shinhyeok Oh, Seungtaek Choi (* equal contribution)
AAAI Conference on Artificial Intelligence (AAAI) 2024
2023
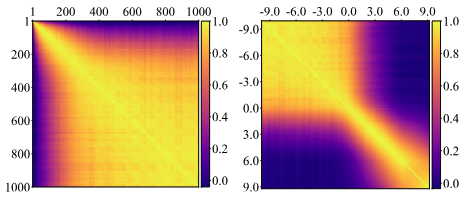
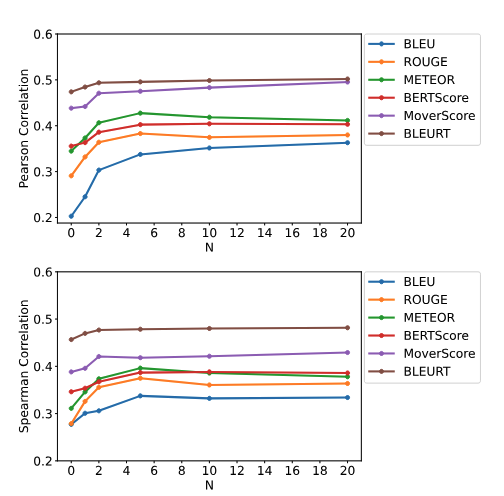
Evaluation of Question Generation Needs More References
Shinhyeok Oh*, Hyojun Go*, Hyeongdon Moon, Yunsung Lee, Myeongho Jeong, Hyun Seung Lee, Seungtaek Choi (* equal contribution)
Findings of the Association for Computational Linguistics (ACL) 2023
Evaluation of Question Generation Needs More References
Shinhyeok Oh*, Hyojun Go*, Hyeongdon Moon, Yunsung Lee, Myeongho Jeong, Hyun Seung Lee, Seungtaek Choi (* equal contribution)
Findings of the Association for Computational Linguistics (ACL) 2023
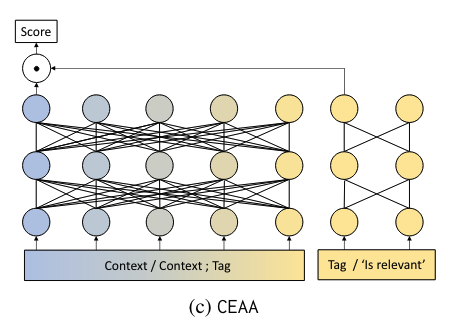
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
Hyun Seung Lee, Seungtaek Choi, Yunsung Lee, Hyeongdon Moon, Shinhyeok Oh, Myeongho Jeong, Hyojun Go, Christian Wallraven
Findings of the Association for Computational Linguistics (ACL) 2023
Cross Encoding as Augmentation: Towards Effective Educational Text Classification
Hyun Seung Lee, Seungtaek Choi, Yunsung Lee, Hyeongdon Moon, Shinhyeok Oh, Myeongho Jeong, Hyojun Go, Christian Wallraven
Findings of the Association for Computational Linguistics (ACL) 2023
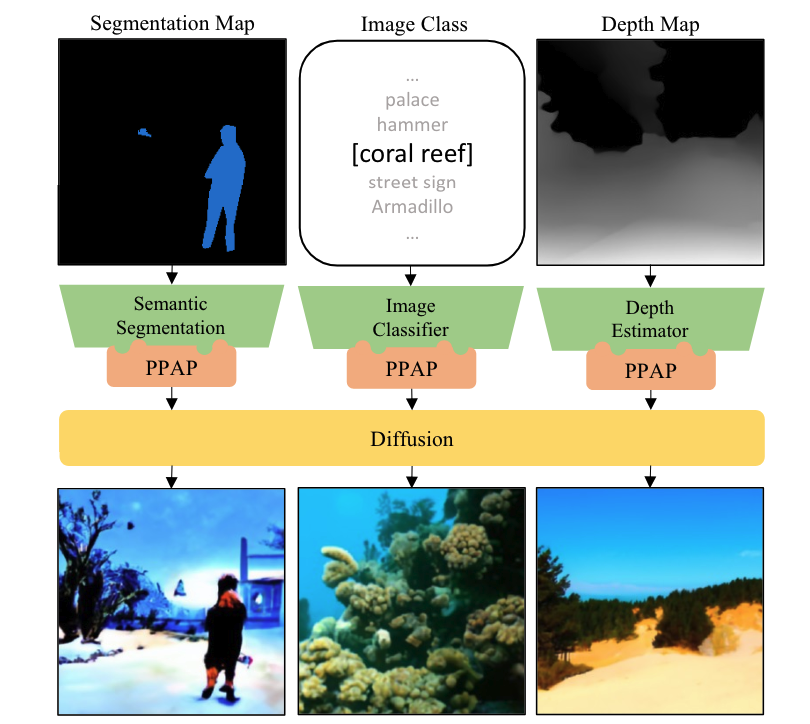
2022
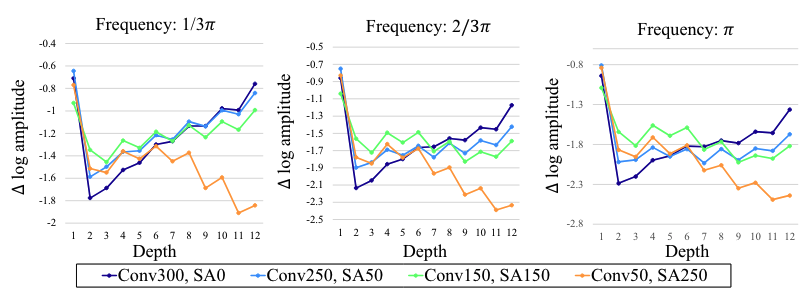
Towards Flexible Inductive Bias via Progressive Reparameterization Scheduling
Yunsung Lee*, Gyuseong Lee*, Kwangrok Ryoo*, Hyojun Go*, Jihye Park*, Seungryong Kim (* equal contribution)
European Conference on Computer Vision Workshop (ECCVW) 2022
Towards Flexible Inductive Bias via Progressive Reparameterization Scheduling
Yunsung Lee*, Gyuseong Lee*, Kwangrok Ryoo*, Hyojun Go*, Jihye Park*, Seungryong Kim (* equal contribution)
European Conference on Computer Vision Workshop (ECCVW) 2022
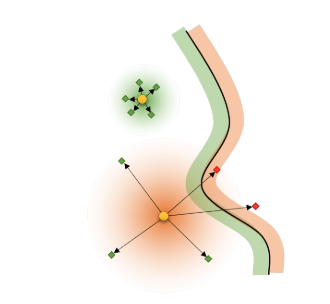
On the Effectiveness of Small Input Noise for Defending Against Query-based Black-box Attacks
Junyoung Byun, Hyojun Go, Changick Kim
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2022
On the Effectiveness of Small Input Noise for Defending Against Query-based Black-box Attacks
Junyoung Byun, Hyojun Go, Changick Kim
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2022
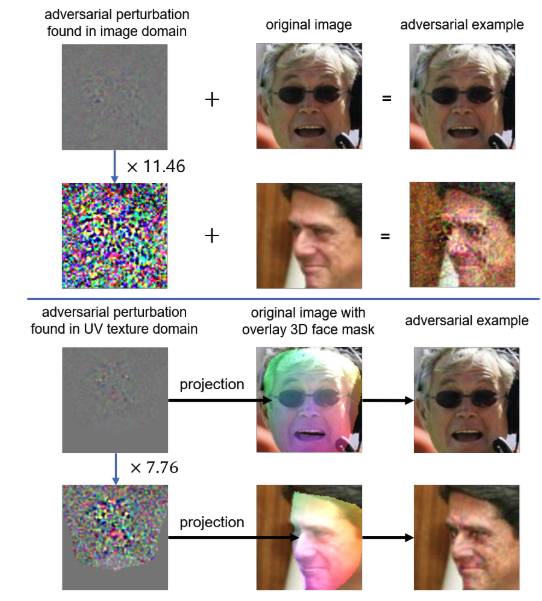
Geometrically Adaptive Dictionary Attack on Face Recognition
Junyoung Byun, Hyojun Go, Changick Kim
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2022
Geometrically Adaptive Dictionary Attack on Face Recognition
Junyoung Byun, Hyojun Go, Changick Kim
IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) 2022
2021
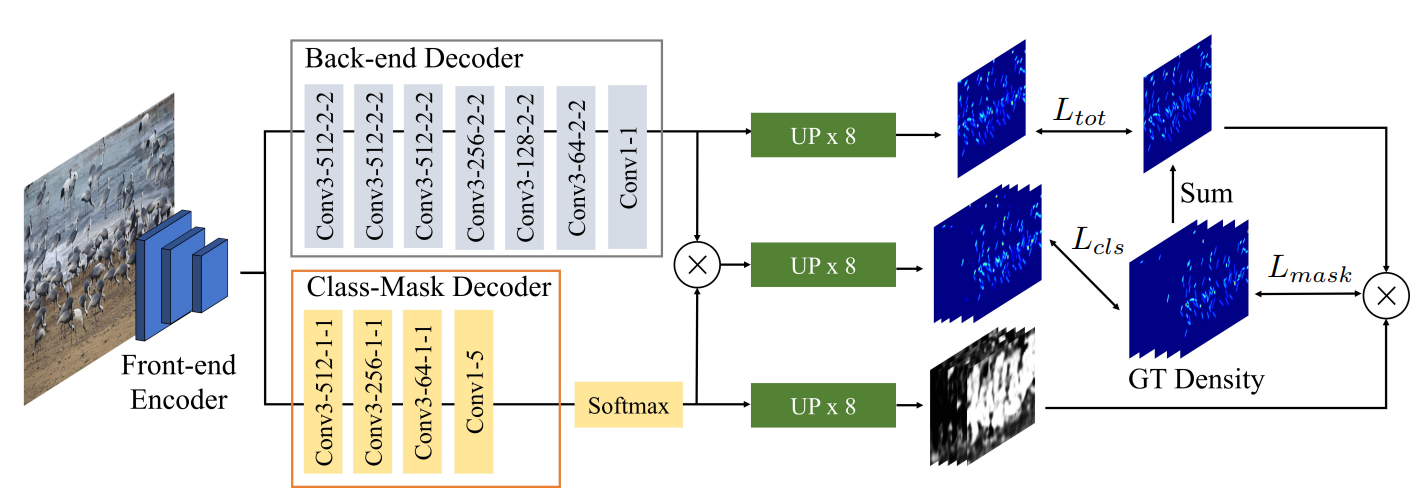
Fine-grained Multi-class Object Counting
Hyojun Go, Junyoung Byun, Byeongjun Park, Myung-Ae Choi, Seunghwa Yoo, Changick Kim
IEEE International Conference on Image Processing (ICIP) 2021
Fine-grained Multi-class Object Counting
Hyojun Go, Junyoung Byun, Byeongjun Park, Myung-Ae Choi, Seunghwa Yoo, Changick Kim
IEEE International Conference on Image Processing (ICIP) 2021