To address negative transfer, we propose leveraging existing MTL methods.
We adopt three MTL methods: PCgrad, UW, and NashMTL.
-
PCgrad mitigate conflicting gradients between tasks by projecting conflicting parts of gradients.
-
NashMTL balances gradients between tasks by solving a bargaining game.
-
Uncertainty Weighting (UW) balances task losses by weighting each task loss with task-dependent uncertainty.
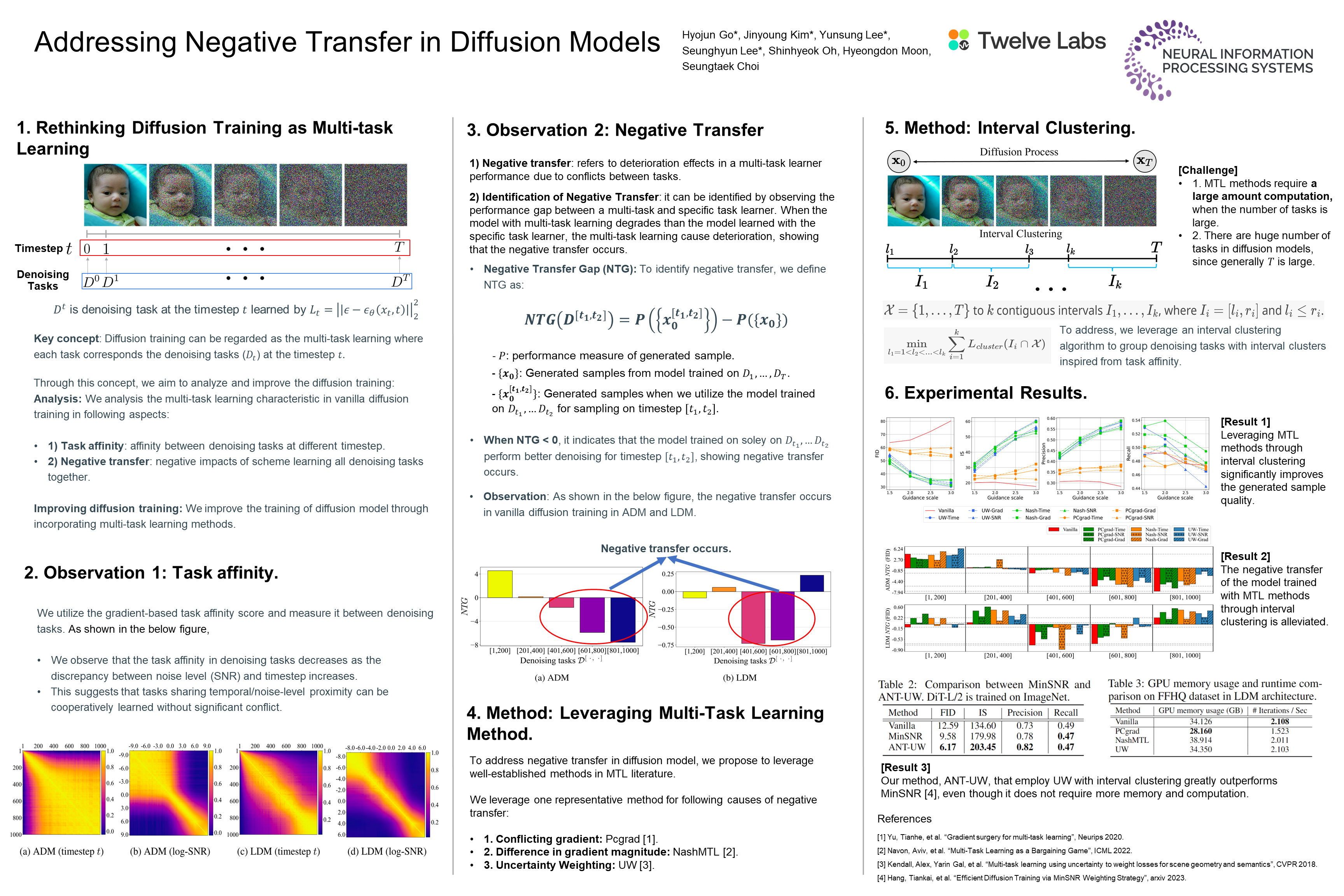
MTL methods can require a large amount of computation, especially when the number of tasks is large.
To address this, we leverage an interval clustering algorithm to group denoising tasks with interval clusters inspired from task affinity,
then, we incorporate MTL methods by regarding each interval cluster as a single task.
In our case, interval clustering assigns diffusion timesteps
\(\mathcal{X} = \{1, \dots, T\}\) to \(k\) contiguous intervals \(I_{1}, \dots, I_{k}\),
where \(I_{i} = [l_i, r_i]\) and \(l_i \leq r_i\).

For \(i = 1, \dots, k\) and \(l_{1} = 1\), and \(r_{i} = l_{i+1}-1\) (\(i< k\) and \(r_k=T\)),
the interval clustering problem is defined as:
$$ \min_{l_1=1 < l_2 < ... < l_k } \sum_{i=1}^k L_{cluster}(I_i \cap \mathcal{X}) $$
We present timestep, SNR and gradient-based clustering cost.






{kind=link}